|
技术科普 | 解锁更智能的工作方式技术科普 | 解锁更智能的工作方式
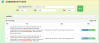
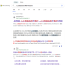
DeepSeek开源FlashMLA,这是其针对Hopper GPU优化的高效MLA解码核,旨在加速推理过程,降低KV Cache使用,提升Context处理能力。项目上线即获热捧,展现了DeepSeek在AI技术创新与开源共享方面的诚意与实力。 Trados 致力于推动创新,为译员和审校员提供更轻松、高效、智能的工作方式。秉持这一目标,我们推出了全新功能——Neural Fragment Recall。这是基于 AI 的下一代 upLIFT Fragment Recall 功能,采用先进的神经对齐技术支持。通过实时提供更精准、一致的片段建议,该功能显著提升了翻译效率。Neural Fragment Recall 现已在我们的桌面和在线编辑器中独家集成了云翻译引擎。 upLIFT Fragment Recall 的功能和局限性 在过去的十年,upLIFT Fragment Recall 一直是我们编辑环境中的一个重要工具,通过检测和对齐部分原文和译文句子,然后在翻译过程中将它们作为片段建议,使翻译记忆库变得更加智能。如果没有此功能,语言专家将不得不手动搜索先前翻译的短语并将其复制到编辑器中,这不仅耗时,还降低了工作效率。 upLIFT Fragment Recall 是一个功能强大的工具,它使用统计方法对字词和短语进行对齐。然而,这种技术缺乏对词语在共享语义上下文中的相互关系的更深层次的理解,这可能导致源词语和目标词语之间错过连接。此外,upLIFT Fragment Recall 还需要相对较大的翻译记忆库(通常在 1,000 到 5,000 个翻译单元(TU)之间),以提供准确可靠的结果。 通过 Neural Fragment Recall 提高效率 当翻译单元添加到 TM 中时,Neural Fragment Recall 会自动对齐原文和译文单词或短语。然后存储对齐数据,从而实现快速,一致的片段检索,并确保翻译与翻译记忆库更新保持同步。 以下是它如何改善您的翻译流程: 实时神经对准:它会自动对齐保存到翻译记忆库中的单词和短语,确保新添加的片段可以快速调用。 无需最小 TM 限制:与前代产品不同,此功能不依赖于翻译记忆库是否具有特定数量的翻译单元才能开始使用。用户可以立即启动并运行 Neural Fragment Recall,从翻译的第一个句段中释放 TM 的全部潜力。 提高一致性:通过依靠神经对齐而不是传统的统计匹配,它每次都能提供更准确和一致的结果。 非常适合减少重复性的内容:对于法律和公共部门的内容特别有用,在这些方面保持一致性至关重要,即使在部门层面的重复率较低的情况下也是如此。 在线编辑器中的 Neural Fragment Recall 图像。附加到项目的 TM 包含两个已保存的翻译单元(句段 6 和句段 7)。以前,由于可用翻译单元数量不足,upLIFT Fragment Recall 不会提供任何建议。使用 Neural Fragment Recall 时,只需一个 TU 即可开始对齐片段并生成建议。 当前,Neural Fragment Recall 功能已支持英语<>德语、英语<>法语和英语<>西班牙语三种语言对,未来将不断扩展到更多语言对。 通过 AutoSuggest 在桌面和在线编辑器中提供片段匹配,译员可以在工作时快速利用结果,从而提高效率并缩短项目周转时间。
|